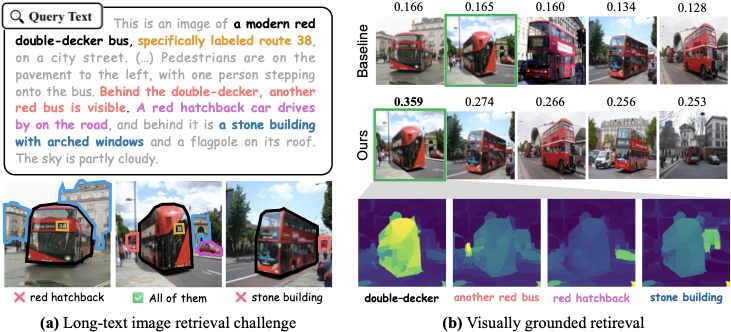
Vision-language models such as CLIP often struggle to faithfully understand long, detail-rich captions, relying on dominant scene cues while overlooking fine-grained visual evidence. We propose a hierarchical vision-language learning principle for understanding scenes as part-to-whole compositions: before forming a whole-scene representation, a model should uncover what semantic parts appear where in the image.
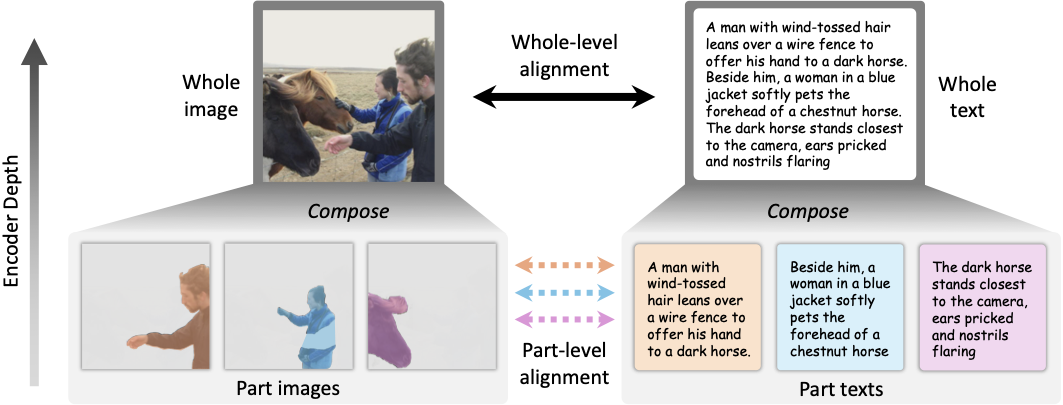
To this end, we propose CAFT (Cross-domain Alignment of Forests and Trees), a vision-language model that jointly learns local text-region alignment at intermediate representations and global image-text alignment at the final representation. Exploiting the organization of long captions, where local descriptions often correspond to scene parts, CAFT employs a fine-to-coarse image encoder and a part-whole text encoder to discover localized part semantics and progressively compose them into a global image-text representation.
Trained on 30M image-text pairs, CAFT achieves state-of-the-art performance on six long-text retrieval benchmarks and exhibits strong scaling behavior. Experiments show that CAFT learns fine-grained representations that localize textual semantics in image regions without explicit region-level supervision.
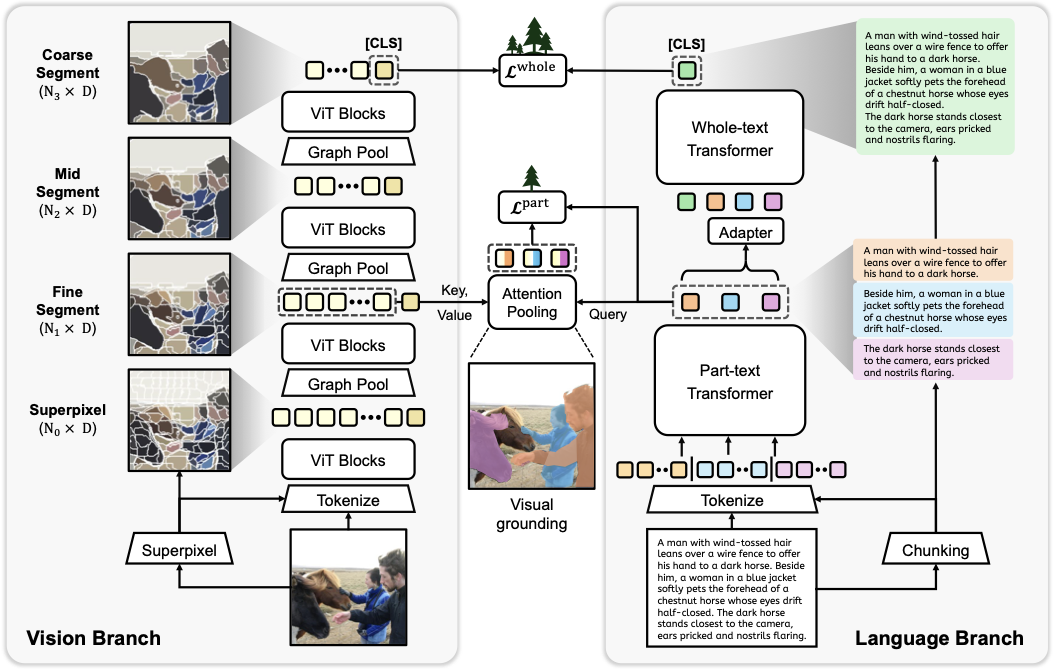
CAFT jointly learns local text-region alignment at intermediate representations and global image-text alignment at the final representation. The vision branch performs fine-to-coarse scene parsing starting from superpixel tokens, while the language branch encodes long captions hierarchically via a Part-text Transformer and a Whole-text Transformer. A hierarchical cross-domain alignment objective ties the two branches together at matched granularities.
CAFT achieves state-of-the-art performance on six long-text retrieval benchmarks, improving R@1 by up to 5.4% over prior methods, and exhibits strong scaling behavior.
